A practical example of the Subset-Sum Problem in modern Python
I love putting on music when I’m working. One of my best acquisitions of 2022 is a Digital Audio Broadcasting (DAB) radio, able to receive a larger variation of radio channels than it’s analog predecessors (AM/FM).
My favorite radio station is continuously playing music, with a fixed break for a news update at the beginning of each hour. However, they don’t sync the selection of songs so that a songs ends right at the end of each hour. This can result in “Paradise by the Dashboard Lights” by Meat Loaf, being cut off after 4 minutes because the news update starts. That kinda hurts.
As a freelance software engineer, I don’t have much free time. The little amount of free time I have though, I love to spend at mathematical challenging problems like this one. Add a little bit of good Python code and my evening is perfect.
Data Analysis
The process starts by looking at and getting familiar with the data. For this purpose, I’m using the Million Song Dataset, which a freely available collection of audio features and metadata for a million contemporary popular music tracks.
From this dataset, I’ve selected specific pieces of information relevant for the analysis, namely song names, artist names and the duration of each song, expressed in seconds.
I’d like to get a good understanding of the statistics regarding the duration of these songs. Let’s create a histogram to see if the duration of the songs follow a normal distribution.
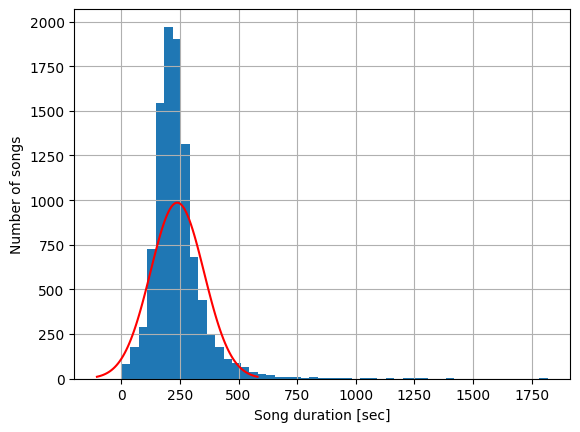
As we can see, the durations of the different songs follow a normal distribution, with an average duration of around 210 seconds (3min and 30sec) and a standard deviation of around 100 seconds. Knowing this, let’s get to the part of designing the song selector algorithm.
Song Selector Algorithm
For the main algorithm, I’d like to have a SongManager singleton class, responsible for the management of selecting which song should be played next. It implements a python iterator object, so next songs can be easily requested by calling the next object using the built in next function, like this:
from typing import List
from song_selector_algorithm import SongInfo, SongManager
titles = [...] # type: List[str]
artists = [...] # type: List[str]
durations = [...] # type: List[float]
songs = [] # type: List[SongInfo]
for title, artist, duration in zip(titles, artists, durations):
songs.append(SongInfo(title=title, artist=artist, duration=duration))
mgr = SongManager(songs)
next(mgr) # The first song is requested and returned
next(mgr) # The second song is requested and returned
mgr.add_songs(songs[:10]) # 10 new songs are added to the songs that can be played
next(mgr) # The third song is requested and returned
Implementation Logic
The SongManager class is a singleton class, meaning there should exist only one instance of this class in the python application. It is initialized with a list of possible songs it could play.
The main working principle is an internal queue of songs that will be played. When the SongManager instance is created, the initial queue is created with a configurable amount of songs, for example 15 songs.
When a new song is requested, two actions occur:
- the first song in the queue is requested and removed from the queue
- the queue is “refilled”
Refilling the queue
Refilling the queue is done in a specific manner, to make sure that at the start of each hour, the latest songs should be almost near completion.
A new concept is considered: the Time To Hour (TTH), denoting the time difference between the moment the final song of the current queue will finish playing, and the start of the following hour.
A configurable duration threshold (for example 15 minutes) is defined as the Threshold Time To Hour (TTTH), which is the period of time which we should consider to activate the optimization algorithm that selects songs to fit the hourly news constraint.
There are three different workflows possible when refilling the queue:
- if the current size of the queue is bigger than the configured size of the queue, no actions are performed
- if the current size of the queue is smaller than the configured size of the queue and the TTH is bigger than the TTTH, a new song is randomly chosen and added to the queue
- if the current size of the queue is smaller than the configured size of the queue and the TTH is smaller than the TTTH, a batch of new songs is added to the queue, minimizing the difference between the completion time of the latest song of the batch and the start of the following hour
Time Optimization Algorithm
For the Time Optimization Algorithm, we have the following situation:
- there’s a specific TTH, which is the current time difference between the completion of the final song in the queue and the start of the following hour
- there’s a list of pending songs we could add to the queue
This is, in fact, a specific case of the subset-sum problem, which tries to find a subset of integers from a larger set of integers whose sum is closest to, but not greater than, a given positive integer bound. More specifically for this case, we’re looking for a subset of songs whose total duration is closest to, but does not exceed the given TTH.
This mathematical problem is actually NP-hard (non-deterministic polynomial-time hardness), as there exist 2^n -1 subsets that could be checked for n different options. If we have only 100 possible songs we could play, this would result in 1.2676506*10^30 subsets we could check.
However, faster and more efficient algorithms have been developed. Also, for this specific case, we are not really interested in knowing if there’s a solution that exactly matches the time constraint. We are, in fact, more interested in finding the set of songs that most closely approximates the time constraint. Following and implementing the Fast Approximation Algorithm for the Subset-Sum Problem from Bartosz Przydatek, I found satisfying results for my use case.
I tested this hypothesis by solving the SSP for 200 different scenarios, featuring TTHs between 100 seconds and 2000 seconds. I plotted the time needed for the algorithm to run for each TTH of the subset sum problem.
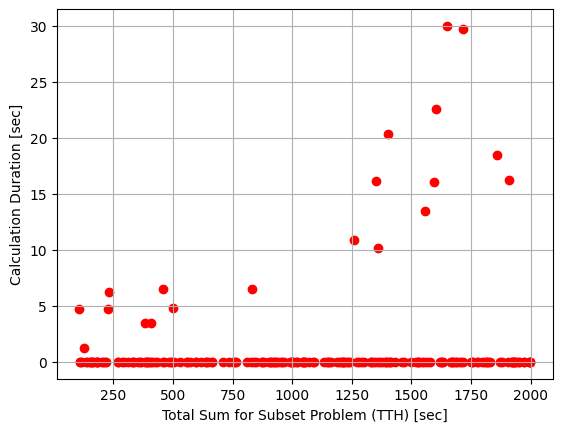
I saw that in most of the cases, the solution is found almost immediately, while for some sporadic cases, more time is needed to find a solution that satisfies the needs of the use case.
Let’s quantify this in more detail by looking at the percentiles of this data:
for quantile in range(90, 100, 1):
print(f"Perc{quantile}: {df.duration.quantile(quantile / 100):.2f}")
Output:
Perc90: 0.15
Perc91: 3.45
Perc92: 4.77
Perc93: 4.96
Perc94: 6.50
Perc95: 10.22
Perc96: 13.57
Perc97: 16.17
Perc98: 18.51
Perc99: 22.65
From here, I could see for example that in 90% of the cases, a solution was found in less than 0,15 seconds.
Apart from the execution time, I’m of course also interested in the obtained accuracy of the results. Let’s plot the obtained accuracy for each of the TTHs:
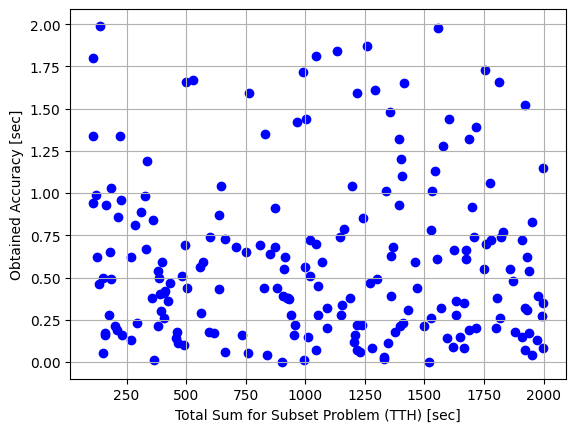
These results are actually more easily interpreted with a histogram:
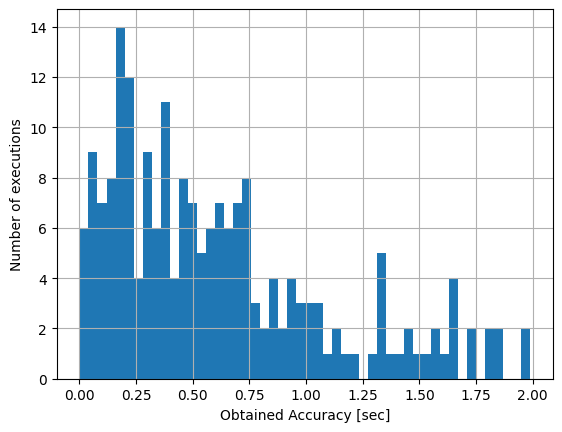
From these results, we can easily see how all 200 songs end less than 2 seconds before the start of the hourly news update, which surely satisfies our needs. Most songs even end less than 1 seconds before the news update should start: spot on!
Code and Development
You can find the complete codebase for this open-source project at https://github.com/GlennViroux/song-selector
Feel free to ping me with questions, thoughts or suggestions!